



近年来,人工智能技术,尤其是大模型的快速发展,正在深刻重塑传统材料科学的研究方式。在钢铁等传统结构材料领域,融合历史知识与人工智能的新型研究模式正逐渐引起广泛关注。基于Transformer架构的大语言模型,凭借其整合大规模数据和挖掘非结构化知识的强大能力,为钢铁设计开辟了全新的方向。这些模型能够高效解析并挖掘历史文献中的隐性知识,为钢铁材料的成分设计、工艺优化和性能预测提供了创新性的解决方案,同时大幅降低了数据准备和特征工程的复杂性。与传统的机器学习方法相比,大模型不仅显著提升了研究效率,还突破了对高质量结构化数据的依赖,为研究者提供了全新的技术支持。这种融合人工智能与历史知识的新范式,不仅在钢铁材料的优化与创新中发挥了重要作用,还为钢铁行业的高效、精准发展注入了强大动力,助力行业迈向智能化的未来。
北京科技大学宿彦京教授团队近期在金属材料领域顶刊《Acta Materialia》发表题为”Steel design based on a large language model”研究论文, 这是《Acta Materialia》首次刊载基于大语言模型进行材料设计的研究成果。该研究提出了一种基于大语言模型的端到端方法,用于从海量历史文本中直接预测材料性能。研究的核心包括材料语言编码器SteelBERT和多模态深度学习框架。通过输入材料成分和工艺的文本信息,该方法能够精准预测材料的力学性能。SteelBERT是在约420万篇材料科学摘要和5.5万篇钢铁相关文献全文的基础上预训练的,可以将化学元素、加工工艺等知识转化为包含上下文信息的向量表示。借助深度学习框架,该方法成功预测了18种不同钢种和工艺条件下的力学性能,其中屈服强度、极限抗拉强度和延伸率的预测精度达到80%左右。此外,通过在实验室特定钢种的小样本数据(64条15Cr奥氏体不锈钢数据)上进行微调,三种性能的预测精度进一步提升至约90%。最终,通过优化钢铁工艺流程,该研究成功制备出性能优异的奥氏体不锈钢,超越了该体系已报道材料的综合力学性能。
论文链接:https://doi.org/10.1016/j.actamat.2024.120663
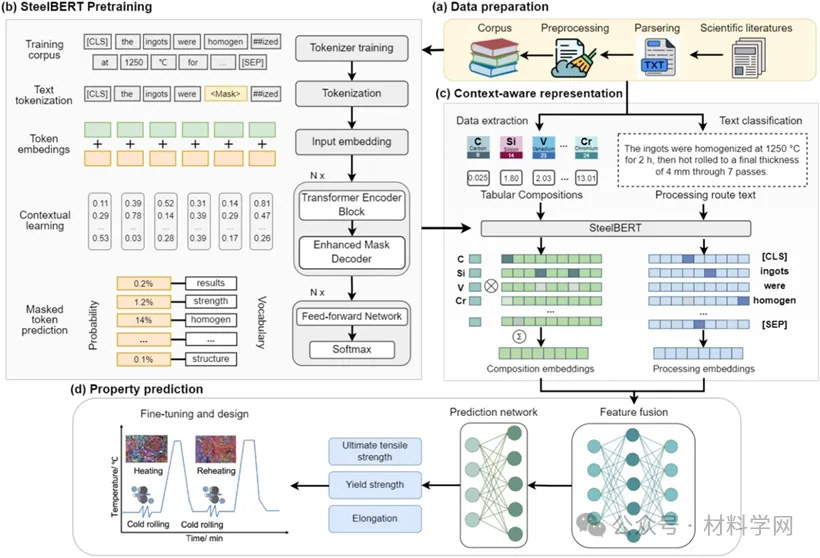
图 1 基于 SteelBERT 模型的力学性能定量预测 (a) 数据准备工作流程示意图。该工作流程包括科学文献下载、语料预处理、表格和文本信息抽取等阶段。(b) SteelBERT 是专注于钢铁材料领域的语言模型,能够捕捉材料相关的上下文信息。(c) 通过 SteelBERT,将文本描述的工艺路线和化学成分嵌入为 768 维的特征向量,为模型提供准确的输入表征。(d)基于自然语言文本的力学性能预测采用深度学习网络构建模型,以嵌入的成分特征和加工路线文本为输入,预测屈服强度、极限抗拉强度及总延伸率。通过在实验室数据集上微调后,成功设计并优化出一种综合力学性能优异的新型奥氏体不锈钢。
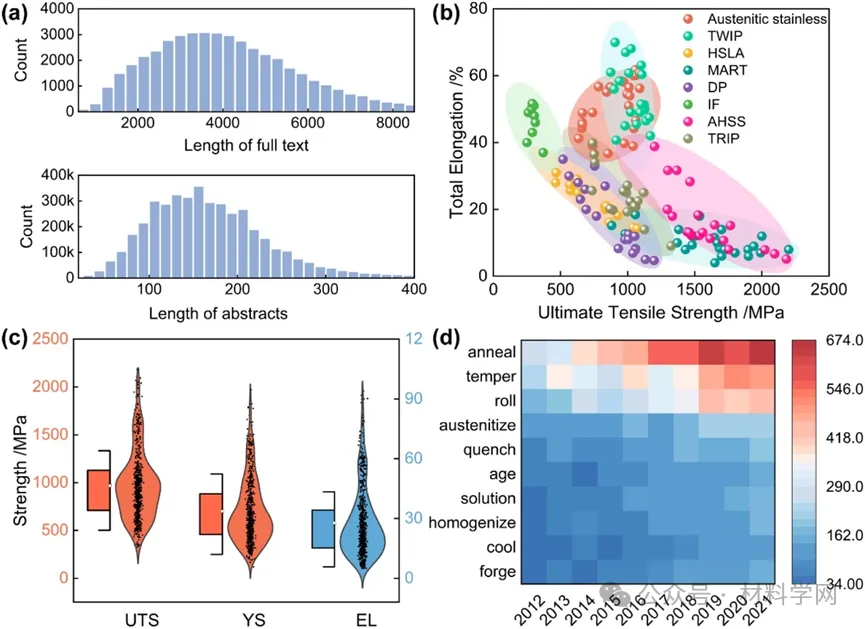
图 2. 抽取数据的语料分布和可视化
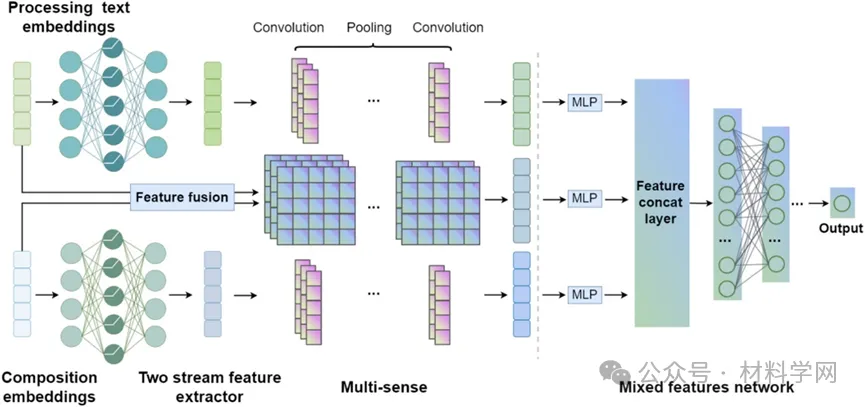
图3 预测模型网络架构
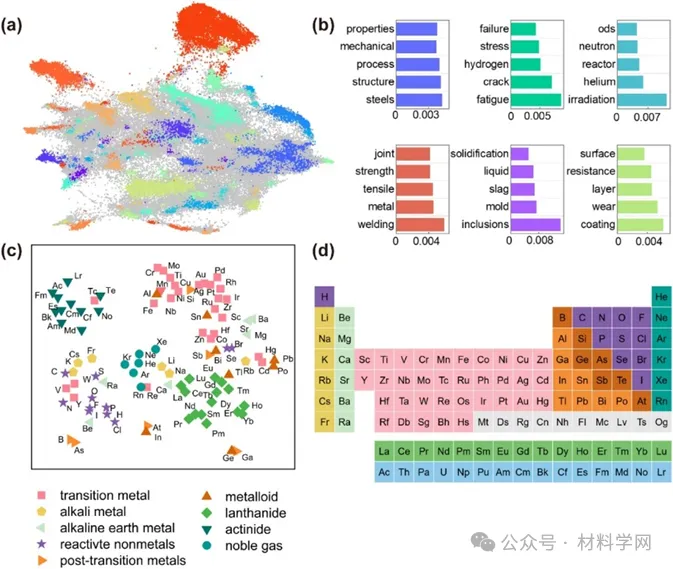
图 4. SteelBERT的可解释性 (a) 利用 SteelBERT 模型进行摘要嵌入聚类的可视化效果。(b) 使用 c-TF-IDF 方法生成主题,以识别每个聚类中的主题。(c) 利用二维 t-SNE 投影来描述 100 种化学元素的词嵌入 (不同颜色表示各类元素的化学周期表)。
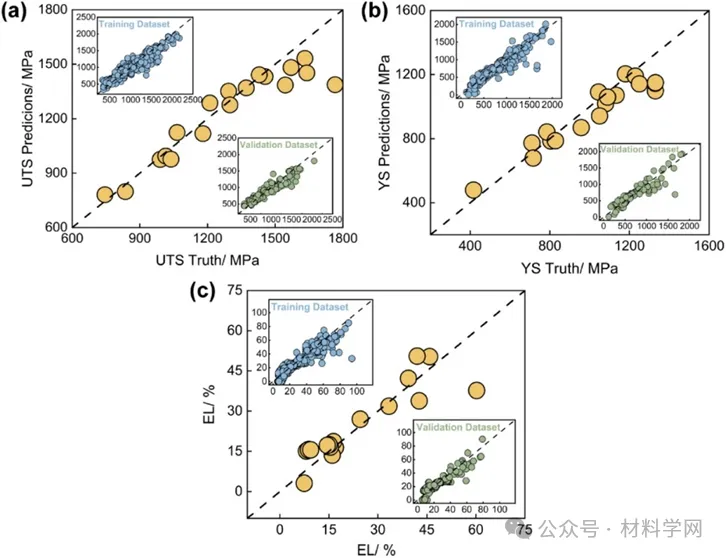
图 5. YS、UTS和 EL 的训练、验证集和测试集性能预测表现
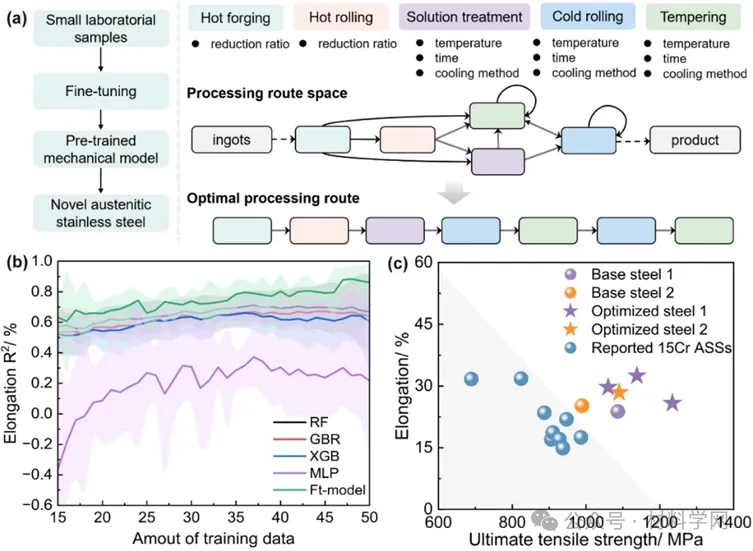
图 6. 新型钢铁的研发设计 (a) 在探索奥氏体不锈钢的小型实验数据集上进行微调的过程。(b) 微调模型与使用 15 至 50 个不同数量的训练数据训练,与传统机器学习模型的比较。(c) 已报道 15Cr 奥氏体不锈钢、初始试样和优化后试样对比。
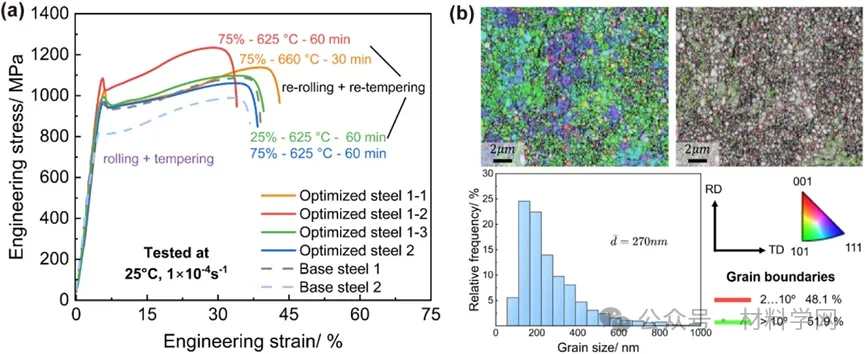
图 7. 拉伸试验和表征 (a) 初始钢与优化后钢在25°C、应变速率为1×10-4 s-1 条件下的应力-应变对比。(b) 优化后钢 1-1 的电子背散射衍射(EBSD)图及其晶粒尺寸分布(轧制方向用垂直箭头标出)。
该研究方法与传统的机器学习方法相比,在解决钢铁制造过程中结构化特征提取、工艺序列对齐以及高维稀疏性等复杂问题时更加高效。此外,在定量回归任务中,其表现优于基于纯Transformer解码器的大语言模型。这一方法实现相对简单,用户只需输入材料成分和工艺的文本信息,即可得到力学性能的预测结果。基于自然语言文本特征开发的这类机器学习模型不仅在钢铁性能预测中展现了巨大的潜力,还能广泛应用于其他材料性能的研究和开发。
【作者介绍】

宿彦京,博士,教授,博士生导师。2000年在北京科技大学获博士学位,同年入选北京市科技新星计划,2005年入选教育部新世纪人才计划。现任北京科技大学新材料技术研究院材料失效与控制研究所所长,兼任“十三五”工业与信息化部产业发展促进中心“材料基因工程关键技术与支撑平台”和“制造基础技术与关键部件”重点专项专家委员会委员,“十四五”科技部“稀土新材料”重点研发计划实施方案编写专家,国家自然基金委“可解释、可通用下一代人工智能技术”重大研究计划专家指导委员会委员。
主要从事材料数据库和大数据技术,以及材料腐蚀和环境断裂研究,在Nat. Commun.、Acta Mater.、Corr. Sci.和npj Comput. Mater. 等刊物共发表论文200余篇,合作出版专著4部,获省部级科技进步一、二等奖四项。“十三五”期间,主持“材料基因工程专用数据库和大数据”国家重点研发计划项目,研发出了材料复杂异构数据存储技术,建成了我国首个集数据库、数据采集和机器学习软件一体化的材料数据库系统;研发出了多主元合金自适应多目标优化算法、量纲约束的符合回归算法、基于自然语言处理的科技文献数据自动抽取技术和程序等。2019年在Acta Mater. 首次发表金属材料机器学习优化设计文章,Elsevier进行了专题报导,被认为是该领域开创性工作。
【团队招生】
论文通讯作者宿彦京教授团队长期招收机器学习方向的硕士、博士研究生。团队研究方向主要聚焦于大模型、深度学习和强化学习等领域,特别欢迎具备扎实编程能力并对材料科学与人工智能交叉研究感兴趣的优秀学生加入。
邮箱:yjsu@ustb.edu.cn
免责声明:本网站所转载的文字、图片与视频资料版权归原创作者所有,如果涉及侵权,请第一时间联系本网删除。

官方微信
《腐蚀与防护网电子期刊》征订启事
- 投稿联系:编辑部
- 电话:010-62316606
- 邮箱:fsfhzy666@163.com
- 腐蚀与防护网官方QQ群:140808414

“海洋金属”——钛合金在舰船的

腐蚀与“海上丝绸之路”